LEAF Lab · University of Toronto
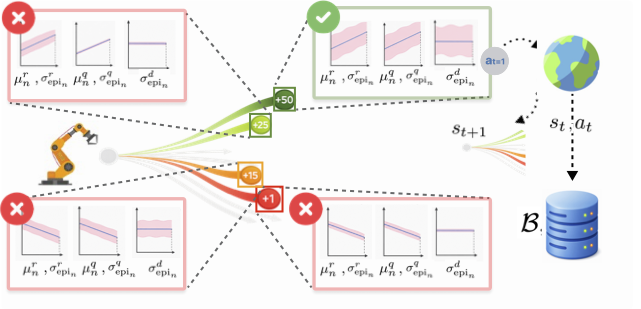
UBP2
Uncertainty-Balanced Preference Planning
* Equal contribution · Learning, Embodied Autonomy, and Forecasting (LEAF) Lab
Preference-Based RL
Model-Based RL
Epistemic Uncertainty
Meta-World
Sublinear Regret